|
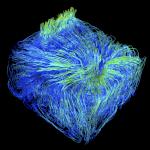
How should work be divided across the nodes of a supercomputer to achieve good load balance and minimize execution time? Supercomputing simulations generate massive data sets, with each time slice containing billions or even trillions of cells. Such data is so large that it cannot fit into the memory of a single compute node. Instead, the data is decomposed into pieces (sometimes called blocks or domains) and each compute node works on a subset of the pieces at any given time. One processing approach is to parallelize over the pieces. In this case, the pieces are partitioned over the compute nodes. For example, if there were ten pieces, P0 through P9, and two compute nodes, N0 and N1, then N0 could operate on P0 through P4 and N1 could operate on P5 through P9. Another approach is to parallelize over the visualization work that needs to be performed. In this case, compute nodes would fetch the pieces they need to carry out their work. This fetching can be from a disk with post hoc processing or from another compute node with in situ processing. There are also hybrid approaches that use elements of parallelizing both over pieces and over work. For each individual visualization algorithm, the key research question is what approach will lead to the fastest execution time. Prior to the founding of the CDUX research group, Hank Childs, along with collaborators, pursued many works considering efficiently parallelizing visualization algorithms for supercomputers, including volume rendering, ray tracing, streamlines, and connected components, among others. For many of the works, the unit of parallelization was not obvious, and the contribution was finding a middle ground between two extremes, i.e., a middle ground for volume rendering between parallelizing over samples and over cells, a middle ground for streamlines between parallelizing over particles and over cells, and a middle ground for ray tracing between parallelizing over rays and over cells. A separate research arc considered the effects of incorporating hybrid parallelism (i.e., both shared- and distributed-memory parallelism). The most interesting findings were for algorithms that stressed communication: volume rendering with multi-core CPUs and GPUs, and again for particle advection with multi-core CPUs and GPUs. In many of these cases, and in particular in the TVCG work by Camp et al., these studies found surprising speedups for hybrid parallelism, due to combined effects from increased efficiency within a node and from reduced traffic across nodes. Finally, Childs led a scalability study for visualization software processing trillions of cells on tens of thousands of cores. The lasting impact of this paper has been to demonstrate the extent that visualization software is I/O-bound, and thus motivate the push to in situ processing. CDUX students have continued to innovate new directions for efficient parallelism. Roba Binyahib did a series of works on efficient parallel particle advection. Her first study extended an existing work stealing approach to use the Lifeline method, earning a Best Paper Honorable Mention at LDAV19. She then performed a bakeoff study, comparing four parallelization approaches, with concurrencies of up to 8192 cores, data sets as large as 34 billion cells, and as many as 300 million particles. Next, Roba designed a new meta-algorithm called HyLiPoD, which built on her bakeoff results to design an algorithm that adapts its parallelization based on workload. This work was awarded Best Short Paper at EGPGV. Her final work on particle advection considered in situ settings, and challenged the common assumption that simulation data should not be moved. Roba also pursued parallelization outside of particle advection, extending Hank's volume rendering algorithm to a TVCG publication. Her study performed experiments that more conclusively demonstrated the benefit of the algorithm, as well as improving on some deficiencies with respect to memory footprint and communication. Other CDUX students have also pursued efficient parallelization. Sam Schwartz also considered parallel particle advection, and specifically how machine learning can be used to optimize settings for frequency of communication and message size. Matt Larsen considered rendering image databases and optimizations for communication that are possible when rendering multiple simultaneously. Finally, Ryan Bleile and Jordan Weiler also improved the state-of-the-art for connected components computations by improving efficiency in communication. CDUX People
Publications by CDUX Students
Publications Prior to the Founding of CDUX
|