|
|
Data Exploration at the Exascale
Project Summary
Recent workshop reports have found that exascale computing would revolutionize science in
many important areas (high energy physics, climate, nuclear physics, fusion, nuclear energy, basic energy sciences, biology, and security).
The most daunting challenge to achieving exascale computing is power:
three orders of magnitude more floating point operations must come from only one order of magnitude more power.
This power constraint will lead to profound changes in how simulations are performed.
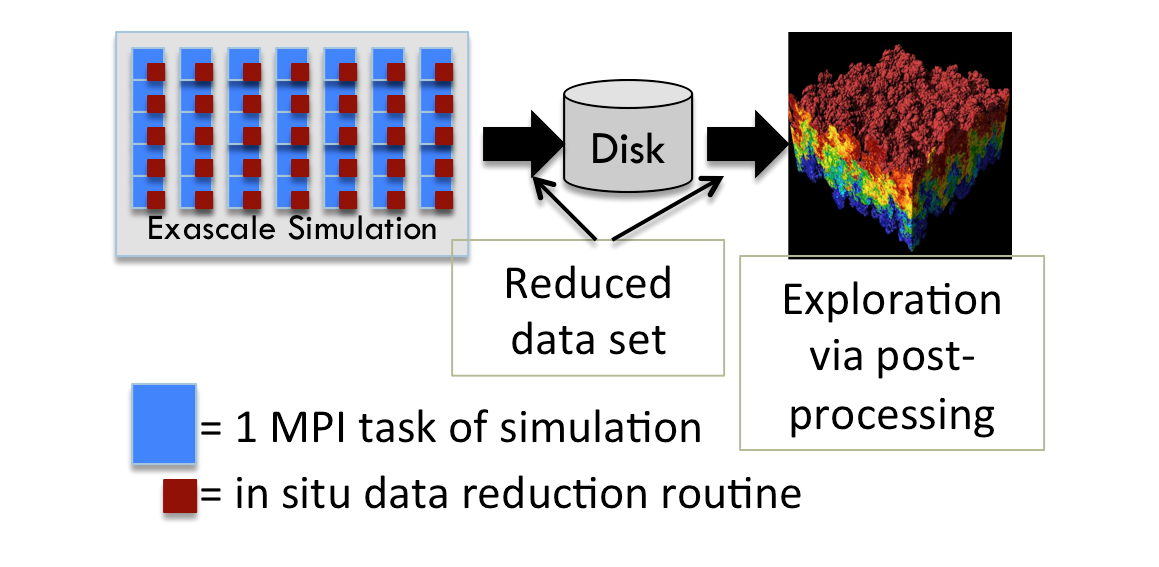
From the perspective of visualization and analysis, the most significant change will be that data must be processed in situ ---
it will no longer be possible to employ the traditional method of writing
full resolution data to disk and
postprocessing it with dedicated analysis applications.
Exploration is arguably the most important use case for visualization and analysis.
It is an iterative process: an analyst forms a hypothesis, poses a question to analysis software,
interprets the result, and then forms new hypotheses and/or additional questions.
It is important because this is the time when new insights are made, when "new science" is discovered.
But exploration is a slow process; analysts form theories on time scales ranging from seconds to days.
Exploratory analysis and in situ processing seem to be fundamentally incongruent.
Traditionally, in situ processing is used when the techniques to employ are known a priori, which is not the case for exploration.
And exploratory analysis occurs on time scales that are too long for in situ processing, that are too long to hold the exascale machine "hostage."
Yet exploration is important, since it enables insights, so the activity cannot be dropped as computing moves towards exascale.
With this project, we are studying techniques that will enable exploratory analysis on exascale simulations.
Our strategy resembles the traditional post-processing model.
The simulation will write data to disk and stand-alone programs will visualize and analyze this data by reading it from disk.
However, we introduce a key new step to this model: we will use in situ processing to substantially reduce the data before writing it to disk.
This approach requires research in three distinct areas:
- What reduction techniques will be able to reduce exascale simulation data to tractable sizes for storage and postprocessing?
- How can we maintain the integrity of the data during reduction? Can we quantify the loss of integrity? Can we increase analysts' confidence in the results by communicate the resulting uncertainty into our visualization and analysis algorithms?
- How can these reduction techniques be efficiently carried out in a billion-way concurrency environment and in a power-efficient manner?
This project is attempting to answer these questions.
We aim to both innovate new solutions and also to evaluate existing solutions and to catalogue the results for exascale simulation scientists.
Most importantly, the project aims to enable exascale simulation scientists to do exploratory analysis.
This is key because exploration is where new science is discovered; this project can help exascale computing realize its value.
This project is funded by a Department of Energy Career award for Hank Childs, which runs through 2017.
Related Projects
This project covers multiple distinct areas. Some of the areas are listed as their own research pages:
CDUX People
Publications
Data Reduction Techniques for Simulation, Visualization, and Data Analysis
Samuel Li,
Nicole Marsaglia,
Christoph Garth,
Jonathan Woodring,
John Clyne,
and Hank Childs
Computer Graphics Forum, September 2018
[PDF] [BIB]
|
Performance Impacts of In Situ Wavelet Compression on Scientific Simulations
Samuel Li,
Matt Larsen,
John Clyne,
and Hank Childs
ISAV 2017: In Situ Infrastructures for Enabling Extreme-Scale Analysis and Visualization, Denver, CO, November 2017
[PDF] [BIB]
|
Spatiotemporal Wavelet Compression for Visualization of Scientific Simulation Data
Samuel Li,
Sudhanshu Sane,
Leigh Orf,
Pablo Mininni,
John Clyne,
and Hank Childs
IEEE Cluster Conference, Honolulu, HI, September 2017
[PDF] [BIB]
|
Toward a Multi-method Approach: Lossy Data Compression for Climate Simulation Data
Allison Baker,
Haiying Xu,
Dorit Hammerling,
Samuel Li, and
John Clyne,
The 1st International Workshop on Data Reduction for Big Scientific Data (DRBSD-1), Frankfurt, Germany, June 2017
[PDF] [BIB]
|
Achieving Portable Performance For Wavelet Compression Using Data Parallel Primitives
Samuel Li,
Nicole Marsaglia,
Vincent Chen,
Christopher Sewell,
John Clyne,
and Hank Childs
Eurographics Symposium on Parallel Graphics and Visualization (EGPGV), Barcelona, Spain, June 2017
[PDF] [BIB]
|
Performance Modeling of In Situ Rendering
Matthew Larsen,
Cyrus Harrison,
James Kress,
David Pugmire, Jeremy S. Meredith,
and Hank Childs
The International Conference for High Performance Computing, Networking, Storage, and Analysis (SC16), Salt Lake City, UT, November 2016
Best Paper Finalist
[PDF] [BIB]
|
Optimizing Multi-Image Sort-Last Parallel Rendering
Matthew Larsen,
Ken Moreland,
Chris Johnson,
and Hank Childs
IEEE Symposium on Large Data Analysis and Visualization (LDAV), Baltimore, MD, October 2016
[PDF] [BIB]
|
Evaluating the Efficacy of Wavelet Configurations on Turbulent-Flow Data
Samuel Li,
Kenny Gruchalla,
Kristi Potter,
John Clyne,
and Hank Childs
IEEE Symposium on Large Data Analysis and Visualization (LDAV), Chicago, IL, October 2015
[PDF] [BIB]
|
Improved Post Hoc Flow Analysis Via Lagrangian Representations
Alexy Agranovsky, David Camp, Christoph Garth, Wes Bethel, Kenneth I. Joy, and Hank Childs
IEEE Large Data Analysis and Visualization (LDAV), Paris, France, November 2014
Best Paper
[PDF] [BIB]
|
Subsampling-Based Compression and Flow Visualization
Alexy Agranovsky, David Camp, Kenneth I. Joy, and Hank Childs
SPIE Visualization and Data Analysis (VDA), San Francisco, CA, February 2015
[PDF] [BIB]
|
Data Exploration at the Exascale
Hank Childs
Supercomputing Frontiers and Innovations, December 2015
[LINK] [BIB]
|
|