|
How can we achieve portable performance for our visualization algorithms over many architectures? 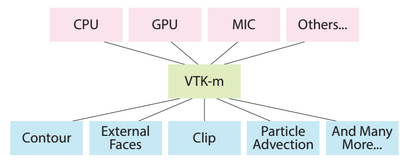
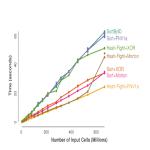
The motivation for this work starts with the Visualization ToolKit (VTK), an important technology for scientific visualization on supercomputers. The project started in the mid-1990s, with core algorithms written in C++, single threaded. In the 2000s, parallelization efforts with VTK primarily involved adding MPI, ignoring possible benefits from shared-memory parallelism (i.e., one MPI task per core). By the early 2010s, it was clear that exascale computing would require many-core architectures, and thus that shared-memory parallelism support would be needed. As a result, a group of Department of Energy researchers and others (including CDUX personnel) came together to form a many-core version of VTK, called VTK-m. VTK contains hundreds of "filters" (encapsulations of algorithms) and represents hundreds of person years of effort; getting VTK-m to be equally functional was (and is) a daunting task. Worse, architectures on supercomputers take varied forms (NVIDIA GPUs, AMD GPUs, Intel CPUs, IBM CPUs, etc.), and can be programmed in different ways (CUDA, TBB, OpenMP, OpenCL, etc.). The developer time to implement the cross-product of visualization algorithms and architectures would be prohibitive, in particular because the set of architectures to support changes over time. Instead, we embraced the data-parallel primitive approach introduced by Guy Blelloch. With this approach, we fix a set of data-parallel primitives (DPPs), e.g., map, reduce, gather, scatter, scan, etc., and build our algorithms out of these primitives. This provides significant savings: adding support for a new architecture entails implementing about a dozen DPPs to run efficiently, which is much better than having to implement hundreds of visualization algorithms. The downside of our approach, however, is that our visualization algorithms need to be re-thought from the perspective of DPPs - a research problem and not a porting problem. In terms of results, CDUX has been a leader in researching DPP-based visualization algorithms. Our initial works came from Matt Larsen, who looked at ray tracing and volume rendering. Matt's ray tracing work informed performance limitations from using DPPs, since he compared a DPP-based approach with NVIDIA’s OptiX and Intel’s Embree. His results were important in making our DPP-based visualization community feel at ease that we were not sacrificing too much performance. Our next work was from Brent Lessley, on the external facelist calculation algorithm. This work required a lot of innovation to fit in the DPP space, in part because it requires hashing. Brent did this in a novel way - hashing items into a hash table without worrying about collisions (last one in wins), and adding subsequent rounds to deal with overwritten items. This approach fit within the DPP framework and avoided atomics, which was important given the platform portability theme. He subsequently compared his hashing scheme with other GPU hashing techniques, and got surprisingly good results. Brent’s Ph.D. dissertation considered two more algorithms with respect to DPPs - maximal cliques enumeration and probabilistic graphical model optimization - and also looked at DPP performance variation over architectures. Additional DPP-based results from our group include novel algorithms for point merging by Abhishek Yenpure, wavelet compression by Samuel Li, and a collaboration on particle advection with David Pugmire of Oak Ridge. CDUX People
Publications
|